Research Note

November 2023 OCP 2023 Draws Networking Crowd
Abstract
OCP 2023 Draws Networking Crowd
Photonics and interconnects rise with AI
November 15, 2023
by Vlad Kozlov and Bob Wheeler
The OCP Global Summit returned to San Jose, California, last month with record attendance. More than 4,400 attendees were treated to a massive quantity of content, with concurrent tracks covering a broad range of data-center topics. The summit is always an important opportunity to hear from hyperscalers including Google, Meta, and Microsoft. For LightCounting, the Special Focus: Optics track was front and center with standing-room-only attendance. Within the Server project, there was a special track on Composable Memory Systems (CMS), which included talks on PCIe and CXL connectivity.
The summit also serves an as incubator through the Future Technologies Symposium—past events have generated new OCP sub projects for forward-looking technologies. The final section of this note discusses a new effort on short-reach photonics. Finally, the summit includes collocated events organized by other organizations, such as the CXL Forum hosted by the CXL Consortium and the SONiC Workshop hosted by The Linux Foundation. The summit’s “big tent” has room for leading vendors, often represented in keynotes, as well as startups seeking feedback and visibility.
During the Optics track, Microsoft’s Ram Huggahalli presented a talk that provided excellent context for later talks on system disaggregation. This talk focused on the requirements for multiple high-bandwidth interconnects in AI training systems, increasing complexity and cost. Huggahalli classified the interconnects into four categories: accelerator-to-accelerator (A-A) remote, accelerator-to-accelerator local, accelerator to CPU (A-C), and accelerator to memory (A-M). To continue to scale accelerator-interface bandwidth requires major efficiency improvements. The talk included target metrics of 5 pJ/b for A-A remote interfaces and 2 pJ/b for the three local interfaces.
Huggahalli discussed memory disaggregation for accelerators, extending the A-M interface beyond a single chassis using optical technologies. At the same time, he promoted a homogeneous approach to the various interfaces to help reduce design complexity. These goals lead to Microsoft’s “North Star” concept, shown in the figure below. It proposes using uniform die-to-die interfaces to connect the accelerator die with protocol-specific chiplets for the A-A and A-C interfaces as well as an A-M expansion interface (in addition to local HBM). The interface chiplets would enable copackaged optics (CPO) for all off-package interfaces, providing enough reach for various disaggregated system architectures. Microsoft also sees the protocol chiplets providing opportunities for customization that are unavailable in a monolithic design.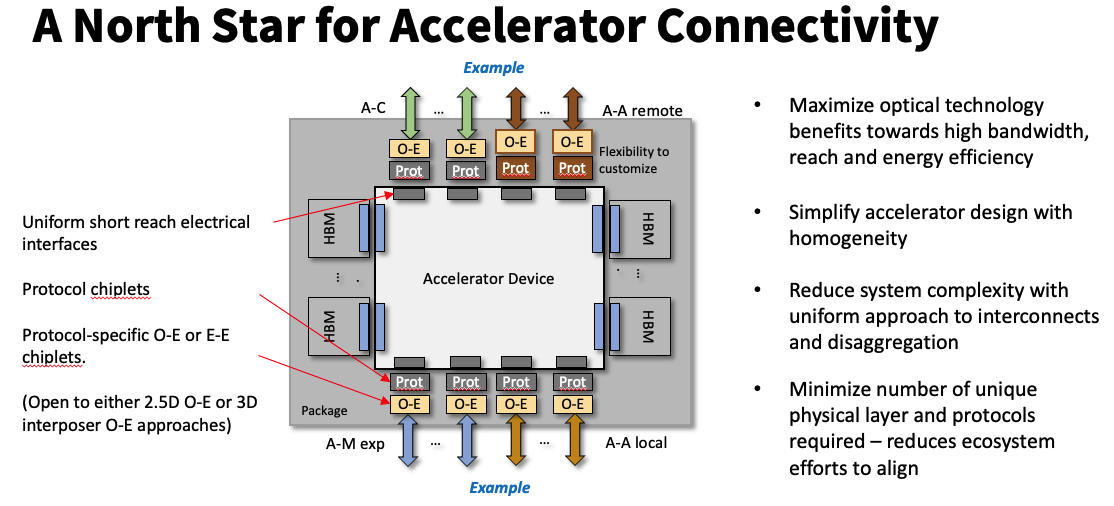
Source: Microsoft
Although Microsoft presented only a concept, it put a sharp focus on the AI use case, whereas the industry’s early work on memory disaggregation largely centered on compute use cases. Given hyperscalers’ shifting investments from general-purpose compute to AI, the CXL Consortium will need to accelerate features for accelerators (including GPUs). The just-released CXL 3.1 specification is a good step, as it fleshes out port-based routing for CXL fabrics and adds peer-to-peer memory accesses. These new features enable GPUs to access shared memory attached to a CXL 3.1 fabric.